Atomicity
"But is this database atomic?"
This is the most common scenario when someone would remember atomicity. However, this is one of the core concepts which is incredibly useful when implementing fault-tolerant systems. It's good to keep it handy and use when reviewing pull requests. In some cases, it might also be very hard to plan ahead.
What is atomicity?
Atom is a definition of the smallest indivisible particle. An atomic operation should perform as a whole or not perform at all.
Why this is useful?
In the real world, things tend to fail most unpredictably. Both software and hardware can fail. If you have dependencies to 3rd party services - or utilise the network in any capacity - that can of course fail. When you are persisting data to a local file or a remote bucket, or reading/writing to a database - any of those operations can fail.
It's generally a good idea to fail predictably, with good logs, alerts and least effect to end-users. It's also nice to have an option to recover from failure. This is not always possible. But when you are limiting ways how a system could fail, recovery becomes a much easier task.
The atomic approach is especially useful when you are implementing jobs processing large batches of data. In this case, you are risking thousands (if not millions) corrupted records when something fails.
Example
Let's say we have a job that validates and processes records in a database. Each record is read, validated using a 3rd party, and then written to 2 different tables depending on the result of that validation. We also mark each original record as "read" so that we could skip it from processing next time.
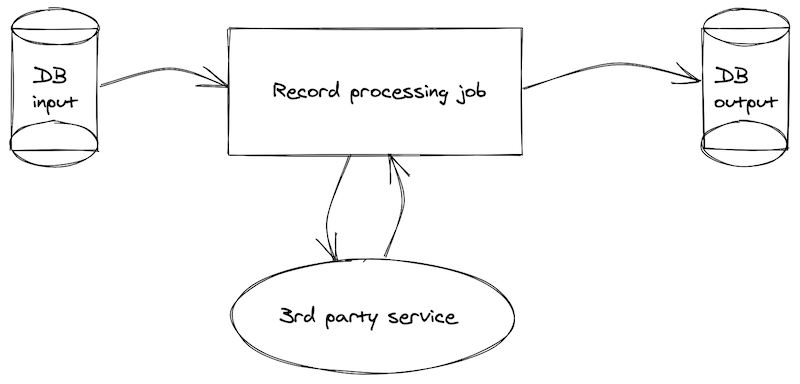
Our pseudocode would look something like this:
originalRecords = readFromDb()
markAsRead(originalRecords)
[validRecords, invalidRecords] = validateWith3rdParty(originalRecords)
writeToTableA(validRecords)
writeToTableB(invalidRecords)Technically there is nothing wrong with this implementation. It will be fine in most cases. We can have proper logging and alerts around it.
However, when that 3rd party service goes down, we will find ourselves in a heap of trouble. Not only we will fail to perform the operation, but also by the time of the fail, a record currently being processes is already marked as "read" on the original record. This means it will fail to process, and will be skipped the next time this job runs.
Even worst - all of the records in the original batch are already (quite optimistically) marked as "read" - meaning the whole batch would not be retried next time when a 3rd party service might be back up.
Identifying weak links
Anything can fail, but the likelihood will vary. It is safe to assume that any 3rd party service could go down at any moment, and your service should be able to recover from this. It is also not productive to expect anything to fail at any moment.
Personal top of things that are likely to fail:
- 3rd party services
- Our services that rely on 3rd party services
- Unexpected input data
- Data persistence (database or a cloud bucket)
- Data read from a database
Things are more likely to fail under an increased load or with a significantly larger batch size than you would usually expect.
Improving atomicity
Batch processing is a good concept for fault tolerance. When a given batch fails, you can restart and try again. In this example, we could be even more granular and implement an atomic operation on a record level.
An improved implementation could look something like this.
originalRecords = readFromDb()
originalRecords.forEach(record => {
validationResult = validateWith3rdParty(record)
markAsRead(record)
if (validationResult)
writeToTableA(record)
else
writeToTableB(record)
})This way we are processing one record at a time. We have also moved a call to the 3rd part service to the very top. This way if it fails, nothing else will be executed. A record would not be marked as read, which means next time when this job runs, it will be automatically retried.
Can we improve this even further? Yes - we could move markAsRead() to the very bottom of the loop. This way we are making sure that a record is marked as read only when all of the operations are successful. A nice atomic approach.
More thinking
Atomicity is a concept, but you can apply it in any situation when a state of a system is involved. It will allow you to gracefully recover from failures and have a more predictable state of your system. Which is good, because the code we write makes a lot of assumptions about the environment.
NASA likes to say that failure is not an option. For the rest of us, failure has to be an option, but it should happen predictably when we can keep the rest of the system from breaking, and be able to easily recover.
Idempotency
"Idempotency is the property of certain operations in mathematics and computer science whereby they can be applied multiple times without changing the result beyond the initial application." - Wikipedia
This might not sound particularly exciting, but it is one of the fundamental tools when building fault-tolerant systems.
I believe the very first time I've heard about idempotency was when reading through Stripe API documentation. Stripe is dealing with financials, which is a very sensitive topic. One of the most common issues on backend systems is when a given operation seems to fail, then it is automatically retried, and suddenly you have performed the same operation twice. This might not be a big deal when you are trying to write a log or send a message - but it is a big deal when you are charging someone's bank card.
Stripe has a whole chapter on Idempotent requests. The way they do it is each request gets assigned an idempotency key - a random-looking alphanumeric combination that is attached to this particular request to perform this particular action. Once you have this key, you are free to retry the same operation as many times as you want - the result will always be the same. Also, a bank card would only be charged once.
Example
If you are dealing with automated jobs charging people millions of dollars on every run - or maybe you are writing software for controlling nuclear reactors - a concept of idempotency has value for you.
Let's say you have a job that would charge a list of accounts late fees on a given day.

It could look something like this.
// pseudo code
lateFeesDailyJob() {
todaysAccounts = getTodaysAccounts()
todaysAccounts.forEach(account => {
accountDetails = fetchAccountDetails(account)
accountMissedPayment = getMissedPayment(accountDetails)
if (accountMissedPayment) {
// is it time to charge a late fee?
if (accountMissedPayment.date + two_weeks === today) {
chargeLateFees(accountDetails)
}
}
})
}This function would be part of a cronjob which is triggered daily. This is all fine, until one day this cronjob fails halfway through the run. Some accounts get processed successfully, while the rest of them never get to be processed. Now you are in trouble - you'd probably want to process the rest of the accounts. However, simply restarting the job would also charge accounts in the first part of the list twice.
You can increase fault tolerance here by modifying the date comparison slightly:
if (accountMissedPayment.date + two_weeks <= today)This way even if your job misses a day or two, it can still catch up the next day and process all the accounts that were skipped the day before.
But what if you have to re-start the job on the same day as soon as the run failure detected? With the current implementation, the same accounts will get processed twice, or even more if you have multiple retries.
Let's make this function more idempotent. To do that we are going to mark an account as charged after we have taken their money.
if (accountMissedPayment.date + two_weeks <= today) {
chargeLateFees(accountDetails)
markAccountAsCharged(accountDetails) // mark record in db
}We will also modify the original function that fetches a list of accounts to be processed to only return uncharged accounts.
todaysAccounts = getTodaysUnchargedAccounts()The whole implementation would look like this:
// pseudo code
lateFeesDailyJob() {
todaysAccounts = getTodaysUnchargedAccounts()
todaysAccounts.forEach(account => {
accountDetails = fetchAccountDetails(account)
accountMissedPayment = getMissedPayment(accountDetails)
if (accountMissedPayment) {
// is it time to charge a late fee?
if (accountMissedPayment.date + two_weeks <= today) {
chargeLateFees(accountDetails)
markAccountAsCharged(accountDetails)
}
}
})
}This way a given account can only be charged once doesn't matter how often you retry this job on the day.
You might also want to combine this approach with atomicity - to make sure that charging late fees and marking an account is reflecting the success of the charge.
result = chargeLateFees(accountDetails)
if (result === SUCCESS) {
markAccountAsCharged(accountDetails)
}At this point, we are in a pretty good place. A cronjob can now be safely restarted multiple times on failure, and each account would only get processed once. A job is well done as I call it.
Documenting business logic in your code
Code documentation has always been a controversial topic. You've probably heard "Code is documentation" mantra, and I 80% agree with it. As long as this is just about the code, and just for the coders. This mantra quickly breaks when you have business logic in your code, which needs to be read and understood by, well, business.
A natural timeline of events might look something like this. A logic is designed and a JIRA ticket is created for implementation. While implementing it, a developer discovers a bunch of edge cases. Logic is refined accordingly and evolved to work flawlessly. Code is tested and deployed to production. A shiny set of unit tests provide an insight into how the logic is supposed to work.
6 months later a product manager tries to understand how the feature is functioning. Remember, it's been in production for a while now. The original spec was never updated, and the only place where business logic is described is code itself. A PM needs to have a deep understanding of the current state of things, however, they can't read code. In some instances, they might not even have access to Github.
At this point, a current developer is asked to document the logic in Confluence. A new shiny page is created where behaviour is described and all is well for now. At least for the next few months.
Engineers are a lazy bunch. We like to do things once and let computers do the rest. Doing documentation feels like doing the same job twice - and in many cases it is. First, you tell a computer what to do, then you explain to a human what you just said to a computer. Can these two things somehow be combined? Well, here's my best shot.
Let's imagine we have a web service for buying cinema tickets.
/**
* # Cinema Tickets Service
* ## Buying tickets
*
* A successful booking will be made of charging a credit card
* and booking seats. If any of that fails, we skip sending
* email confirmation and refund a possibly successful charge.
*/
const buyTickets = (customerData: Customer) => {
Promise.all([
chargeCreditCard(),
bookSeats(),
])
.then(results => sendConfirmation())
.catch(error => report(error));
}
This looks sort of like jsdoc, but instead of describing input arguments of a given function here, we have a human-readable documentation of the business logic. In markdown.
Since we can't have code as documentation, here's the next best thing - having documentation next to the actual code. This way it can be written and updated as part of the same PR changing the code. It will also help a new dev on the team to understand the context of the code. This is not about the what this code is doing - it is about why this code is doing what it's doing.
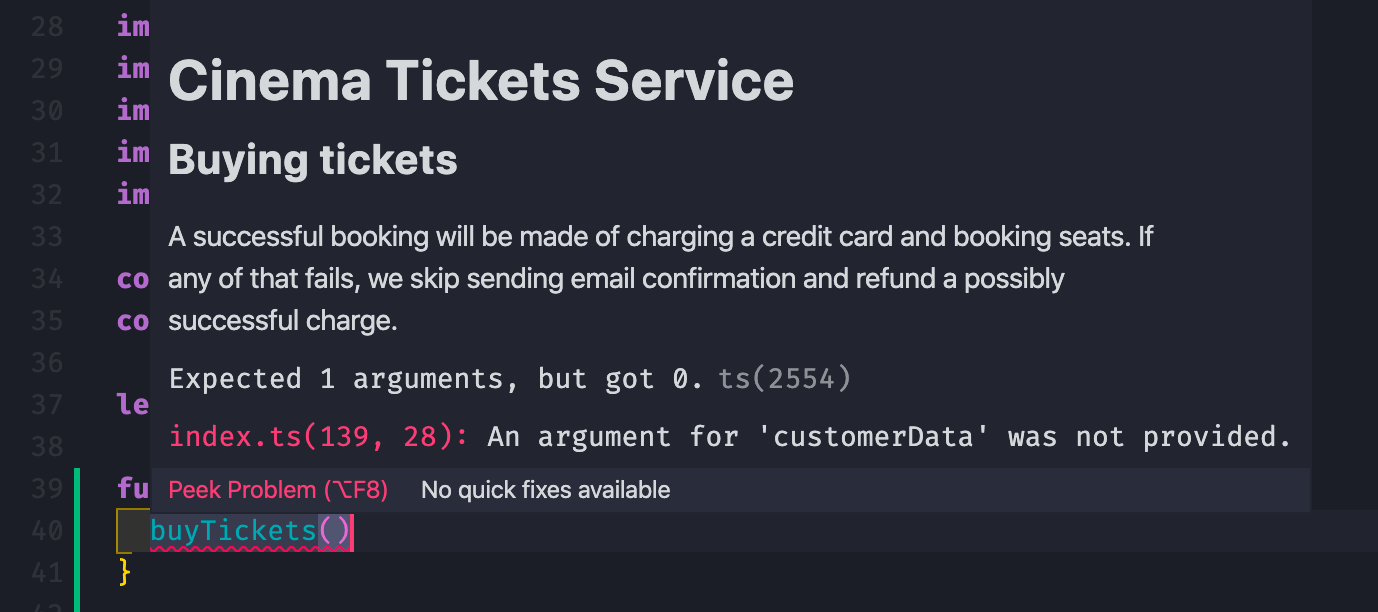
A nice perk of VSCode is that it will render markdown into a human-looking rich text when you are going to use this function elsewhere.
Sharing context is an undervalued problem - many things are assumed as obvious - generally by people gained context while spending years in a given company or a project.
In the next part of this series, we are going to talk about how to generate documentation from the blocks of markdown comments scattered around the codebase. Stay tuned!
Remote Work
My current company - a UK energy startup - has always had this ongoing remote work mindset. I thought I'd share a thing or two how we made it work for us.
In short - although we are mostly a traditional "work from office" company, for a software developer there's nothing that would stop you from being 100% productive while working remotely.
Step 1: No meetings Wednesdays
This was a tiny idea that quickly became integrated into our culture. On Wednesdays we have no meetings. This also means you can from from anywhere. You can come and work from the office. You can fly to Budapest and work from there. Whatever works for you.
Most of our product teams are working from home on Wednesdays, and this has created an environment where we had to test and maintain our toolset and best practices. Our VPN has failed a couple of times, issues were addressed and now it is in a great shape and I haven't had a connectivity issue in ages.
Step 2: VPN
As a fundamental security precaution, connectivity to business critical resources should be limited to the office network or a VPN. This means a reliable VPN setup, able to handle a load of every developer, QA and data scientist connected to it simultaneously. Load testing a VPN before going 100% remote is a great idea.
Step 3: Culture
Work from home is not the same as remote work. This has been highlighted a few times now in HackerNews discussions. We are not really doing remote work, but more like enabling office type of work from any chosen location. This means most of the teams are starting work at 9am and finishing at 6pm. This means we don't do async work, but instead everyone are more or less synchronised even on WFH days.
This is not neccessarily a bad thing.
Synchronisity allows interoperability. It means you can easily switch between working in the office and working remotely at any given day, not just on Wednesdays. It allows pretty good flexibility in terms of when you need to work from home - you don't have to adjust your working patterns, everything mostly stays the same.
This means, there is no effect on your personal productivity. Things continue the usual way.
So yes, morning standups happen every day, everyone turns up - on site or online, and we plan together the new day ahead.
Step 4: Meetings and informal catch ups
Slack and Google Hangouts are all the tools you need really. But you have to build a culture of using them in the most efficient way.
Slack
Have a channel dedicated just to your immediate team. Encourage ongoing chat about who is doing what and if there are there any blockers. This is like a sound of an engine - you know it's working when there is rumbling going on.
An alternative would be to periodically ask everyone who is doing what right now. This is counter productive and can be perceived as annoying micro management.
Hangouts
Every meeting should be available on Hangouts by default. Ideally, every meeting should also be recorded and available to view later, but there might be some privacy concerns there. At the very least, you should be able to join every meeting via a phone line.
Hangouts are pretty handy also when you want to have a quick informal catch up. Those are irreplaceble - and often are an argument for working from office. When everyone are in the office, you can interrupt and talk to any of your co-workers at any moment, right?
Not really. Even in the office, even when sitting side by side there are good and bad times of interrupting your teammate. We try to indicate those moments by having a headphones on policy - when I have my headphones on, treat this as a do-not-disturb sign.
Now when it is a good moment to catch up, you might as well use Hangouts to do a bit of pairing, discuss a particular feature detail or do a mob review of a particularly challenging pull request. Reviews over Hangouts work equally well, if not better - no need to lean over each other around a laptop screen, you can hear everyone well (especially true when your office is a huge open space), and there are clear turns when it comes to providing feedback.
Step 5: Team autonomy
Team autonomy is probably the single most important enabler of remote work efficiency. Every team member should be able to deliver features either independently, or with the minimum interaction with the rest of the team.
This doesn't mean everyone decides for themselves what they are working on. In a traditional setup you would have sprints, goals and pre-defined tickets that are commited for delivery. Each team would hold refinement sessions when tickets would be created, fleshed out and readied for implementation. Dependencies would be highlighted and resolved. Once the sprint starts, you can pick up a ticket from the sprint backlog and start cracking.
At this point there shouldn't be much stopping you from delivering a ticket all the way to production. There might be some gates to open - QA would potentially be one of them. You might want to implement automatic pipelines for QA, or you might be lucky enough to have a dedicated QA engineer on your team. However the case, each engineer should be in a position to pick right tools for the job, do the job, test it and ship to production. And then verify it on production. And maybe create some alerts for a business critical feature.
There is a danger of siloing here when every team does things in their own way. You can easily mitigate this with a good open engineering culture.
Good engineering culture
Have a tech guild wide presentation on the things you've been shipping and challenges you've been solving recently. Extrapolate good solutions into easily reusable libraries, and encourage others do the same. Have an ongoing company-wide tech chat on Slack. Once a month we also do a mini tech conference in the company when anyone can come up and talk about practices they'd like to spread across the company.
Coffee
Most importantly, don’t forget to get out of home for a nice walk to support your local coffee provider. Not every area of London is equally well covered with fancy cafes, but I feel like this situation has improved significantly in the past years. Keep your steps count up, even when your office is 5 steps from your bed.
Leaving Instagram for Open Web alternatives
"What, you're not using Instagram? Where do you post your photos then?"
This question came up a few times recently in conversations with my friends, so I thought I'd write a more detailed explanations.
I've been an active user of Instagram for a number of years. Daily logins, thousands of posts. Never became a proper IG celebrity, or even a micro-influencer - but I've had my fun following a significant amount of users posting pics from film cameras. It's been a long time since IG purists demanded IG is only appropriate for pictures taken on a phone camera. Doing that today would be your direct path to failure, since there are a billion users with the latest iPhone cameras, and every single one of them wants to become an influencer.
You have to be more inventive to win the game today.
Do you remember a time when all photos where forced to be a square? Oh, and a good selection of frames?

The answer to a question why you shouldn't use Instagram today have a few slices, so let me try and split this cake a little.
You are a product
I don't really like ads. I mean, it's totally justified for an online product to use ads as a revenue stream. Often, ads are the only viable revenue for an online service.
I used to like Instagram ads - they did nail the targeting thing and at some point it was recommending relevant events and things I actually was interested in. Lately however it feels that Facebook is grasping for increasing revenue. Facebook's core product is accessible via browser, hence ads can be blocked with extensions. I'm sure they are not happy about it. Instagram technically has a Web version, but it was deliberately strangled in order to push people towards the native app. This is where the majority of users are, and this is where FB has total control over the content.
This is where you can crank the revenue all the way to 11.
There are tricks for blocking ads in the native apps, but none of them will work with Instagram as I'm pretty sure that will block the rest of the content too. And, let's be completely honest, when you subscribe to services T&C:s, you also agree to watch the ads.
The only other fair alternative is that you stop using the service and leave.
API
Instagram used to have a nice API - a way for third parties like myself and yourself to build an alternative client with unique features to access pictures, leave comments, schedule posts and enjoy the experience on iPad - the core team been ignoring tablets forever. The bad news is - FB wants to strangle the third parties and stop them from existing.
The reason is easy enough - you don't have control over ads on those side apps, hence they don't contribute to the revenue. Why should you invest into features that don't contribute to your KPI:s? How are you going to get that quarterly bonus?
With the third party apps gone, the rest of the users will be forced to use the main client app, have all the latest features. And ads.
A sense of a timeline
Algorithimic timeline is great in some ways. Your best friends' pictures are always on top. The first picture is guaranteed to capture your attention and a like. One of the success metrics for the timeline team (I'm sure) is that top post must always get your like or comment. Because second post is an ad, and you'd want to scroll to see it after the success of a first post.
Algorithmic timeline is also a perfect tool for creating echo chambers. To guarantee your likes and satisfaction you will only be displayed posts from your previous likes and current desires, which means less relevant to your current mood posts will be pushed out of your timeline. People you follow become merely a number on your followers count.
In the current political climate of deliberate division I feel like algorithmic timeline might be a single most powerful feature that can bring extremely awful people to power.
I also like chronological timelines. I like how in Google Photos I can just scroll to a June 2017 and pretty quickly find what I'm looking for. Things will probably become more complicated once I'm old enough to loose track of time, but hopefully that'll take a few more years for my brain to soften on the social media apps.
Restricted access
One problem with closed platforms is how do you share your content with someone, who isn't there? There is instagram.com browser version of the app, which allowed anyone to view my stream of photos. React - the most popular JavaScript framework of all times - was literally invented as part of that project.
As of right now, you can still access my account online on https://www.instagram.com/alexsavinme/ . As soon as you arrive, you will be prompted to log in by a not insignificant banner at the bottom of the page. If you dismiss the banner and start scrolling through the pictures, you will be stopped by a proper overlay forcing you to either login or sign up. There is no way of dismissing that.
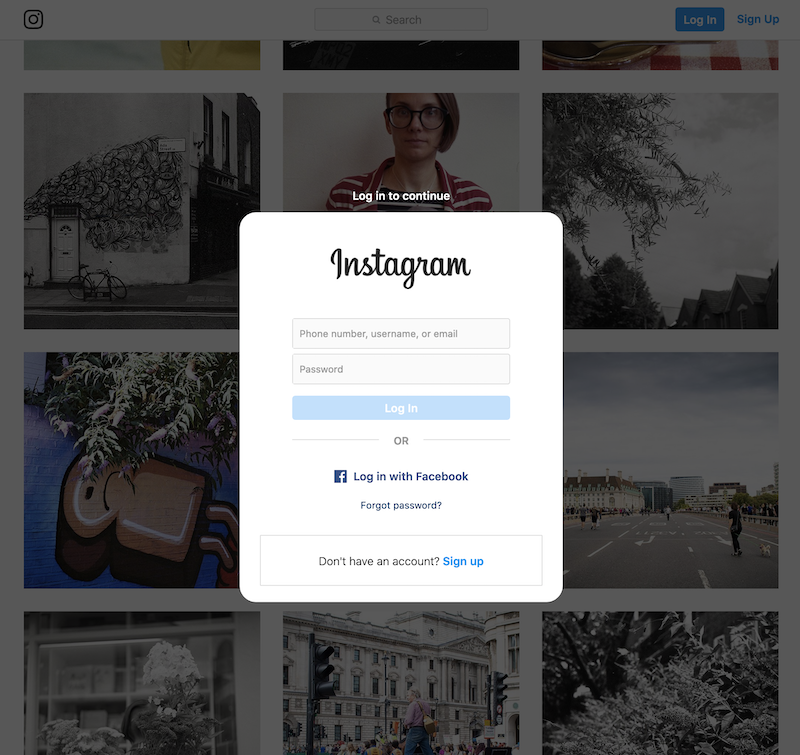
So much for the open access.
Alternatives
"This is all great" - you might say. "But there is literally no competition right now. Well, maybe TikTok."
Lately I've been following the Open Web movement, and they have a few options in a form of open source, decentralised, anyone can host this apps. Decentralisation and openness are probably two key things that matter the most to me.
Pixelfed
One of the direct competitors to Instagram is Pixelfed - https://pixelfed.org/ It is a web app which anyone can host. The clever twist here is that every instance can communicate with each other using a standard called ActivityPub. This way the network is decentralised, but you can still follow users from other networks, and everyone can like and comment on each other's photos.
You can post stories too.
At the moment of writing there are no native apps for Pixelfed, however their Web version works beautifully.
![]()
You can follow me here: https://pixelfed.social/alexsavin
If you decide to join Pixelfed, here are all the available instances: https://the-federation.info/pixelfed
Price: free (if you join one of the hosted instances)
Micro.blog
Not a direct competitor to Instagram, more like a slow Twitter sort of service, which also fallbacks nicely to Open Web standards. It is what is written on a tin - a service allowing you to post small blog posts. You can follow friends too.
Here's mine: https://alexsavin.micro.blog
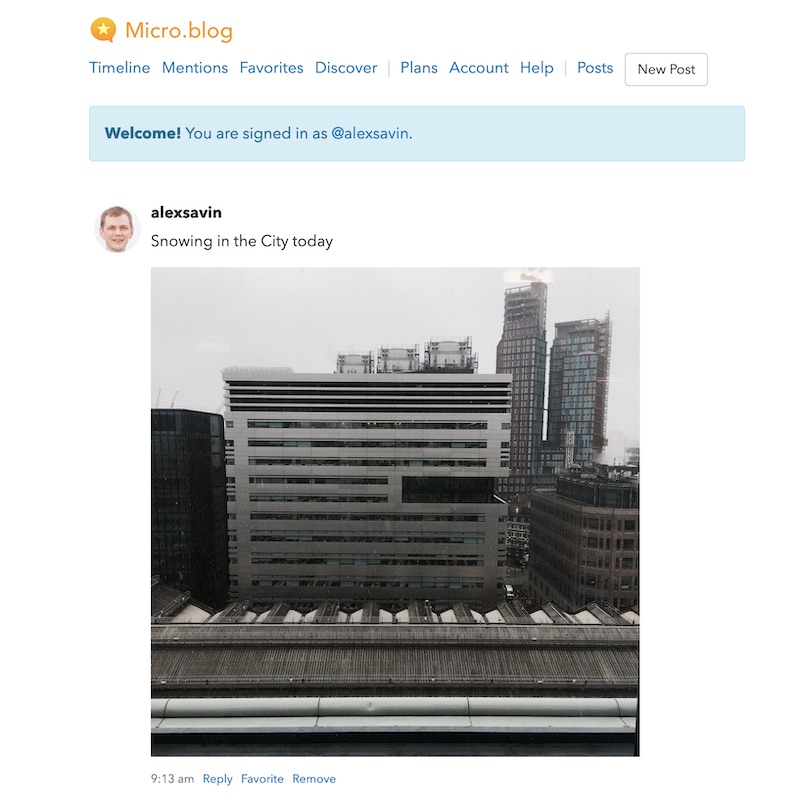
It looks just like a homepage, and there is RSS feed to subscribe to, if you are not a user of Micro.blog but still would like to keep an eye on new posts.
Yes, RSS is alive and kicking, there are still amazing clients like Newsblur to subscribe to feeds and read latest updates. In fact, 95% of all podcasts are distributed via good old RSS. And there is an argument if you can call podcast a podcast if it is not available via RSS.
Microblog allows you to post pictures too. And they have something called emoji tags - it's when you use an appropriate emoji to signal the type of the content in the current post. This in turn enables discovery of photos (and books, and movie recommendations, and music) that users posted on the platform.
I mostly use Micro.blog as my Twitter replacement + open bookmarks registry. The community is nice too. You can fave posts, but also you get thoughtful comments and some of the greatest discussions with strangers on the Internet.
There is a native app for iOS and MacOS too.
Price: 5$ / month. This gives me hosted version of the service, so I don't have to host it myself. And, hopefully, helps the creator of the service to keep it up.
Flickr
It's still around - now saved by Smugmug, which tries to figure out what to do with it. I mainly use it as my main full res photo storage for all the film scans. There is no limit on how big a single photo can be - or it is incredibly high.
There are some unique communities still around on Flickr - one of highlights would be stereoscopic photo communities, and anaglyph in particular. If you have a pair of red/cyan glasses handy, you can discover tons of 3D photos on Flickr for your personal enjoyment.
My personal Flickr (been going since 2008): https://www.flickr.com/photos/karismafilms/
Cost: £4.50 / month
Openness
I should probably mention that every single above mentioned service allows public access to your public posts and photos for everyone with a link, with no need for registration or SMS. This is quite literally the fundamental principle of the Web how it was invented and intended to be used. It was also how the Internet was different from a bunch of other networks that existed long time before - everyone are invited, anyone can learn HTML and post your own webpage in no time. Also, you could view the source code of anyone's webpage, learn a trick or two, and use them on your own page.
These times are mostly gone now. Viewing page source on the Web is mostly reserved for software developers.