Shadow Testing
What is your release pipeline? It probably looks something like this. You write some code, add unit tests, maybe an integration test. Run it on your machine, then push to a CI and see if the build is green. Maybe test it on staging if you have one. Then - deploy to prod.
What usually happens next is that real-world users break your app. Not deliberately, of course, there's no pre-meditated evil intention. There are a few biases we have as software developers, and one of them is that if a feature is well specced and unit tested with 100% code coverage, it'll work just fine on production.
Except it, of course, won't. The real world will always have more edge cases that you can spec in your JIRA ticket.
Your freshly released feature might work just fine until it hits one of those cases when input data is not properly validated, or even manually entered directly into a database. In a rush. With typos. And then you'll have an unhandled exception, carefully captured and reported to Sentry. I hope you are not writing software for space rockets.
"But wait", - you'll say. - "Isn't this the usual circle of life? You write code, it breaks, you report a bug and fix it".
It totally is, and in most cases, there's absolutely nothing wrong about it. Most of us are never trusted with writing software for space rockets, nuclear reactors or financial instruments that automatically trade in millions of pounds. That's of course until you find yourself in charge of a team building a space rocket, and a JIRA ticket (sized as a medium) titled "MVP of a rocket, must not explode".
Shadow testing is a technique that can help you with that.
It's not going to help you launch the first rocket though. For that, you'll have to rely on your usual set of tests. But once you have a regularly scheduled rocket in place, it'll help you updating this rocket in a safer, less explosive way.
Hello, my name is Alex and I'm in charge of Revenue Assurance tech at one of the fastest-growing energy suppliers in the UK. We have over 1 million members right now, and significant cash flow.
Traditionally, energy business works like this - you burn some electricity, and then pay for it. The bill is generated monthly, and this is when you're expected to cover your energy usage with cash. In the UK we also have this thing called Direct Debit - this is when you agree for a company to charge your bank account directly, doesn't matter if there are sufficient funds or not. In the ideal situation, everyone is paying for the things they buy or use. However, once your business grows, you'll start having something called revenue at risk.
Revenue at risk is literally what it says on the tin. Some of the hard-earned money that belongs to you, and you are entitled to receive, is not coming your way. Parts of it can be delayed, and some of it will never find a way to your bank account. This is where Revenue Assurance comes in. They can think of the reasons, why the cash doesn't flow and find ways to make it do so. In an ethical, user-friendly way, of course.
For example, we have a set of cronjobs that can automatically detect failed payments, match it to a customer, check their circumstances and decide if we want to send a reminder about it. This is not a happy message you would like to receive in the morning, but it is something that could potentially prevent you from going even further into debt. This is also not a message you would want to receive by a mistake.
"But hey" - you'll say. - "Just copy the whole database into a staging one, and test as much as you want."
This was sort of ok until very recently when GDPR was introduced. Even before, copying sensitive customer data left and right was worrisome - but now this is completely illegal.
You could however, construct a version of staging data derived from production data. Names and addresses obfuscated, with non-sensitive data replicating current state on production. This is useful for some use cases - but not very useful to us, as we intend to send emails and other forms of comms. Besides there's also a replication delay between prod and staging data - about a week if you're lucky, and over a month if you're not.
What is the worst possible outcome?
This might be the most important question you have to ask yourself when releasing software. If everything goes horribly wrong, what sort of harm this can do? Is it something we can contain? What are the rollback procedures?
Depending on your answers you can decide what sort of testing you need. Facebook's famous mantra used to be "go fast and break things (as long as you can quickly fix them)". The worst possible outcome for an early Facebook was that someone's status update would go missing. On the other side of the spectrum are banks, transportation and space tech. The potential for harm is huge, and rolling back is tricky or impossible.
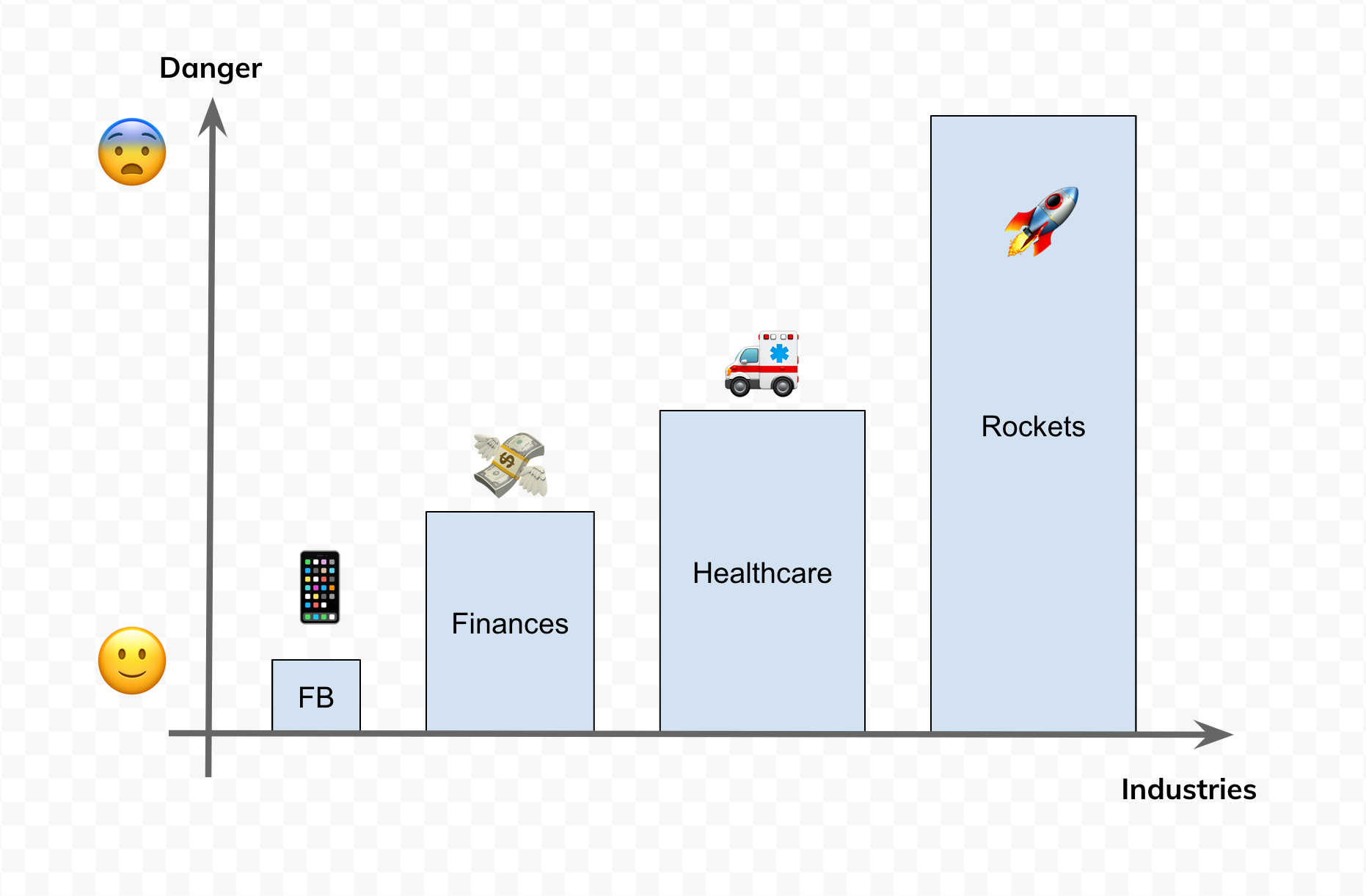
Where are you on this spectrum? For me, it is somewhere in the middle.
A traditional approach
At Bulb, we're pretty good at code quality. We do peer reviews. We have automated CI builds. Unit tests are a must, and a code coverage tool will post its report to a pull request. We have a staging environment, everything runs in Docker containers, and what you test is exactly what gets shipped to production. This gets us very far on the scale of confidence when releasing to prod.
But not to 100%.
There are a few things can go wrong and it is very difficult to predict it while still in the staging environment.
So what is the fine line between staging and prod?
- Production data consistency. Although the schema is well defined, the actual data can be unpredictable, and there is no way of knowing all the edge cases beforehand. Things have improved a lot though with us moving to Typescript and translating data typings into the code.
- Performance issues. Our staging environment is a replica of a production one, but it is not exactly 1:1. Certain operations that are fast in staging can be very slow in prod. Timing also matters, and while things can be fast at some hours of the day, they can become slow at other hours.
- Integration with 3rd party services. Almost every service nowadays has a development environment where you can test things, but again - in real prod situation things can behave differently, and exceptions can be thrown when you least expect them.
- Integration with internal services. Something that can be tested with a good integration test in a staging environment. However integration tests are bad at discovering edge cases, and again - ideally you want to run it against production data to get to the real thing as close as possible.
None of this might be a problem for you. The question you should be constantly asking is - what is good enough? How much confidence is enough confidence? And what is the plan when things go wrong?
(the plan is - rollback the deployment and data, of course, but this is like a whole other topic)
An improvement
At some point in my job, I was tasked with implementing an automated system reminding our customers about missing payments. An initial version was fairly simple, was tested internally on staging and then on production with a group of brave beta testers. All was good, and it was successfully released.
Sometime later an improvement had to be released. Now this job was running against millions of customer records, daily. How do you test for regressions? How do you make sure the existing customers are not affected?
To make things more interesting, there are multiple stages a given customer is progressing through. At any moment you have thousands of cases at different stages of the process, and you want for our customers to never notice any transition to a newer version of the process.
My first idea was to look at production data we have gathered so far, extrapolate use cases and write a lot of unit tests. This could work. I would also have to maintain that huge set of tests and constantly be on the lookout for new cases - which are extremely tricky to identify.
My second idea was to release the change to production and see if anything breaks. But in a safe way.
We are talking classic reliability engineering here, but before things hit the fan. Imagine a way you could throw features to production, but if anything breaks only you would know about it.
Shadow testing
A feature is released in shadow mode. It is there, in production, running side by side with the real thing.
Step 1: Your shadow instance receives live data. It processes the data and logs everything. In the end, it logs the result and doesn't actually mutate the state of the system.
Step 2: Your master instance receives the same live data. It does the same logging of all the decisions and actions.
Outcome: Now you have 2 sets of logs - shadow and master ones. They were fed with the same input data. Have they behaved expectedly and produced the desired result? We can find out this by simply diffing the logs.
Shadow testing is not a new thing - big companies with business-critical software are using it all the time. Tesla is using it to test autopilot features in its cars around the world. They push candidate updates to a selected group of cars without users ever knowing about it.

A candidate runs in shadow mode along with the master, receives inputs from the cameras and sensors in the real world and makes autopilot decisions, which are logged and sent back to Tesla servers for post evaluating. The only other alternative would be learning from actual car crashes. But that's, you know, hard to rollback.
Implementation
Remember the part when a candidate instance in shadow mode is not supposed to modify the state of the system? This is the real key to shadow testing.
If you zoom out a little bit out of your app, you can see a larger picture where there's data coming into the app, and actions happening as a result. Some of the data could be persisted in a database. Emails could be dispatched. Phone calls could be made. A webpage could be rendered. What we want is for our app to be able to pretend to do all these things but not actually doing any of that.
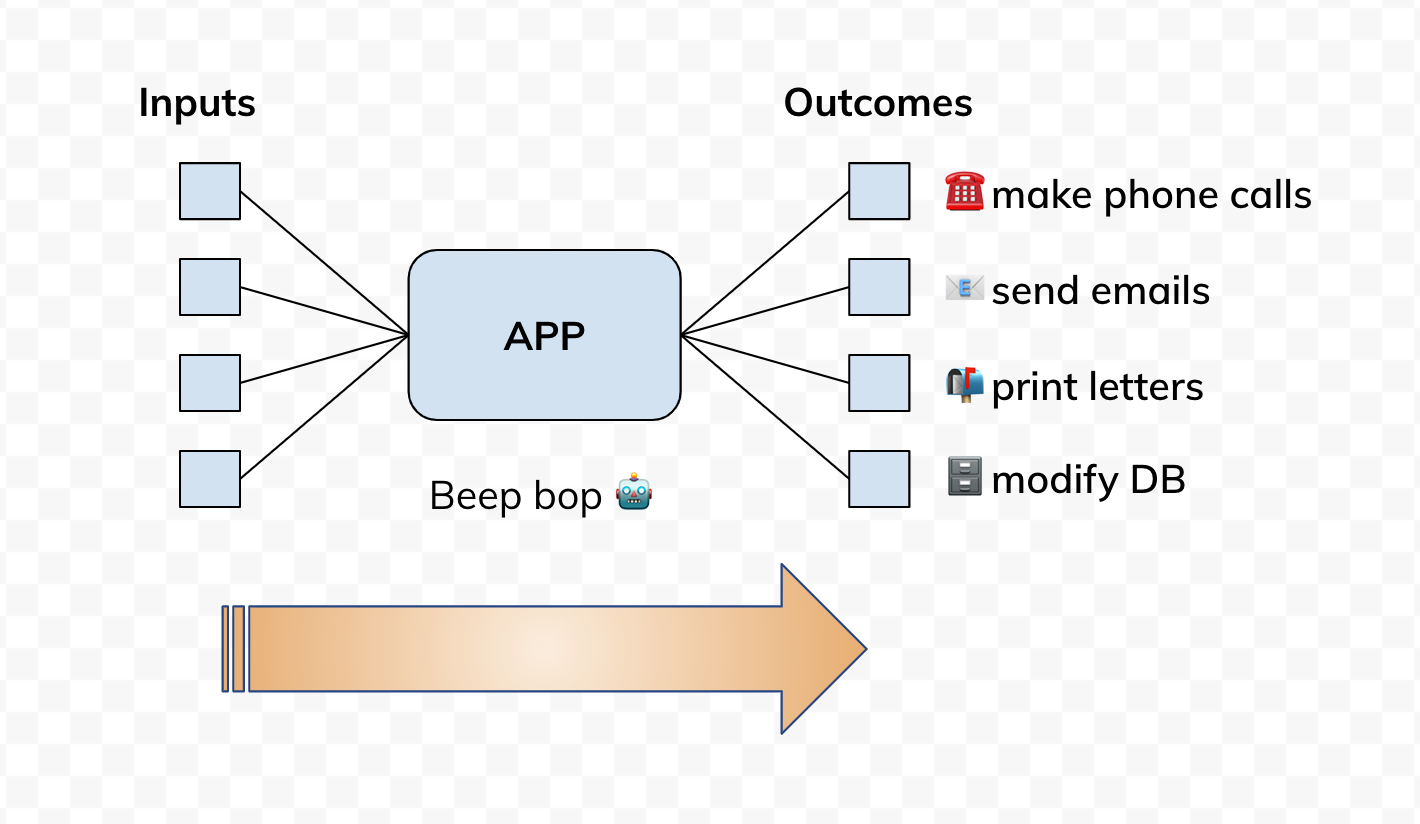
Once you have identified all possible ways how an app can modify the state of a larger system, you'd want to implement a special flag. When this flag is enabled we want the app to run in a harmless mode where it receives production data, processes it and logs what it would do (instead of doing all those things). In our app, we called it toothless mode. When enabled, the app would become completely harmless and instead would simply log its intentions to change the state of the system.

You might want to rethink your approach to logging. Logs are the key to shadow testing and they should represent an accurate sequence of actions, as well as intentions to modify the state - aka results of the run. Every intention to state change should be logged, as this is how you will be detecting regressions in the behaviour of your app.
First run
Once you have toothless mode and logs in place, you are ready for shadow testing. In our case, we run our apps as cronjobs once a day - so a single run has a clear beginning and an end. If your app is a service which is always up, you can run a shadow instance side-by-side. Depending on how actions are triggered in your app, you might have to think about routing this trigger to both instances simultaneously. For example, if your service is triggered by an HTTP request, you want this request to land on both shadow and master instances, with the same inputs.
It is entirely possible that your app modifies system's state in a way that it affects shadow instance. For example, during the run, your app requests data from a remote source, but also the same data is modified as one of the outcomes. This is not an ideal situation, and an immutable approach is always preferred. In the ideal world, your app is like a pure function, takes inputs, produces outputs and never mutates input values. However, if this is the case, you probably want to first run shadow instance, collect logs and only then run the master instance.
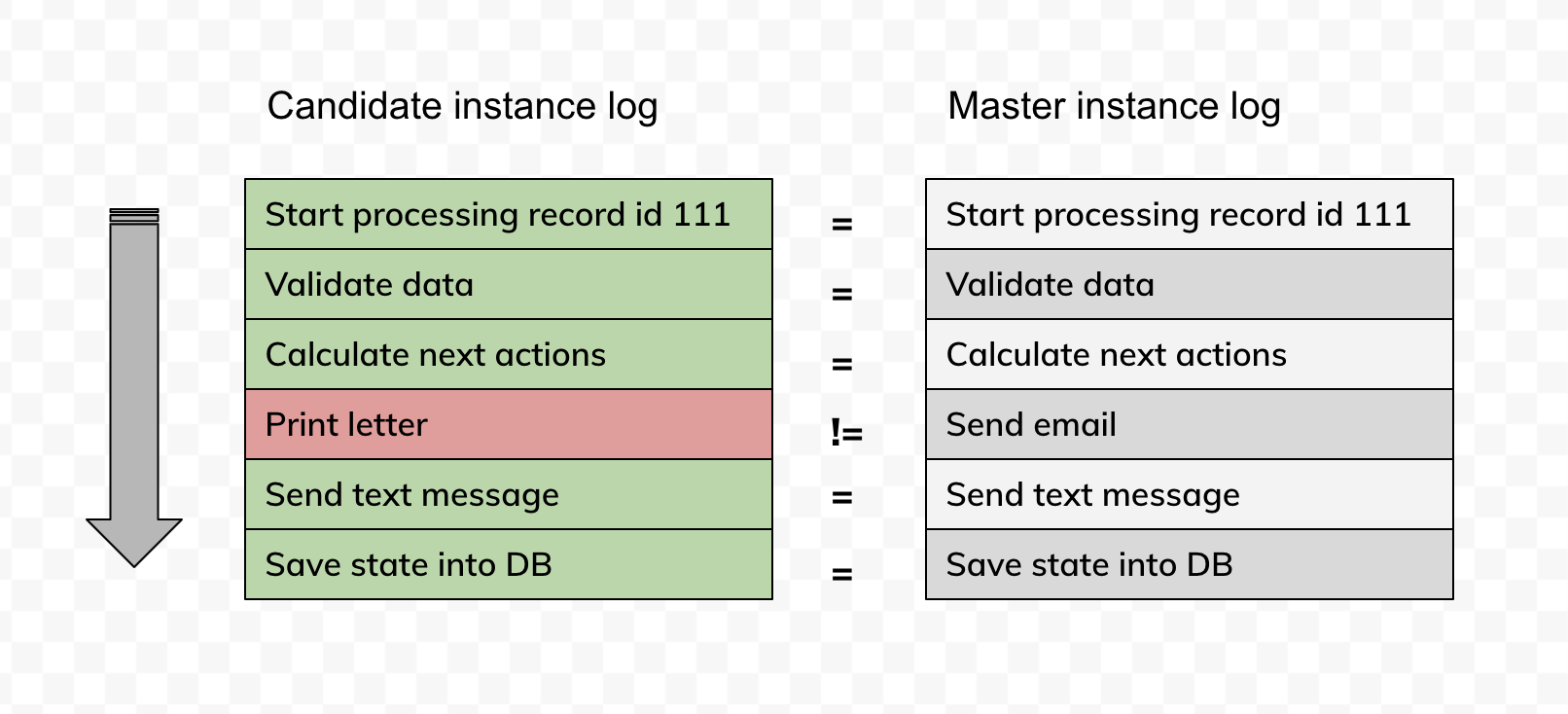
Here's the side by side comparison of the master and candidate logs running in production against the same input data. If they match 100% - there are no regressions or change in behaviour.
Collecting logs should be a simple case of tailing everything into a file. Some systems would also offer you auto-saving logs into a cloud storage bucket, which can be handy if you have huge logs and it takes a significant amount of time per run. Once you have your log files, you'd want to make a visual diff. VSCode is pretty good at this.
Concurrency
The sequence of events is important in shadow testing. A regression can express itself not only through bad output but also with a different sequence of actions performed. If you're using concurrency in your code (think promises), you will find out that the sequence of data processing is not guaranteed. Your diff will reflect this with chunks of logs shuffled around. Simply put, if your code uses concurrency, direct diffing of logs is not a good option.
Instead, you'd want sorted logs.

This is also the first step towards structured logs. You'd have to think a bit on how you'd want your logs to be sorted. Most importantly, you'll have to get rid of timestamps in your logs, as they generally confuse sorting functionality.
We use account ids. They are unique, always consistent and related to a given account that is being processed. Once sorted, you can easily spot regressions, even though the sequence of the events is now shuffled. Once you have detected the regression, you can switch back to the original log and restore the real sequence of events.
Tools
VSCode is a pretty good tool for starters. It has a built-in diff tool which will let you easily compare two files. You can also sort all the logs in case there was a concurrency issue and simple diff is not working out for you.
Things are easy when you have two separate files from shadow and master runs. At the moment we have an arrangement when logs are automatically uploaded into Google Storage bucket. Basically, all logs are dumped into the same file, and a new file is started on every hour. A single run can span across multiple files, and the same file can contain traces from both shadow and master runs.
Originally this wasn't a problem, as you could retrieve logs from a k8s deployment after it has finished running. However there is a limit on how many logs can be stored, and once you hit it, you will only get last ~10k logs. Google's recommendation is to setup logs streaming into a storage bucket, which is precisely what we did.
Now, it is possible to manually sort logs out of log JSON files. It is also not a particularly exciting task. Especially if you have to do it over and over again. So we implemented shadow test tools. It is a collection of scripts that can parse a group of files, pick the logs for both shadow and master runs, separate them and also structure them for easier comparison.
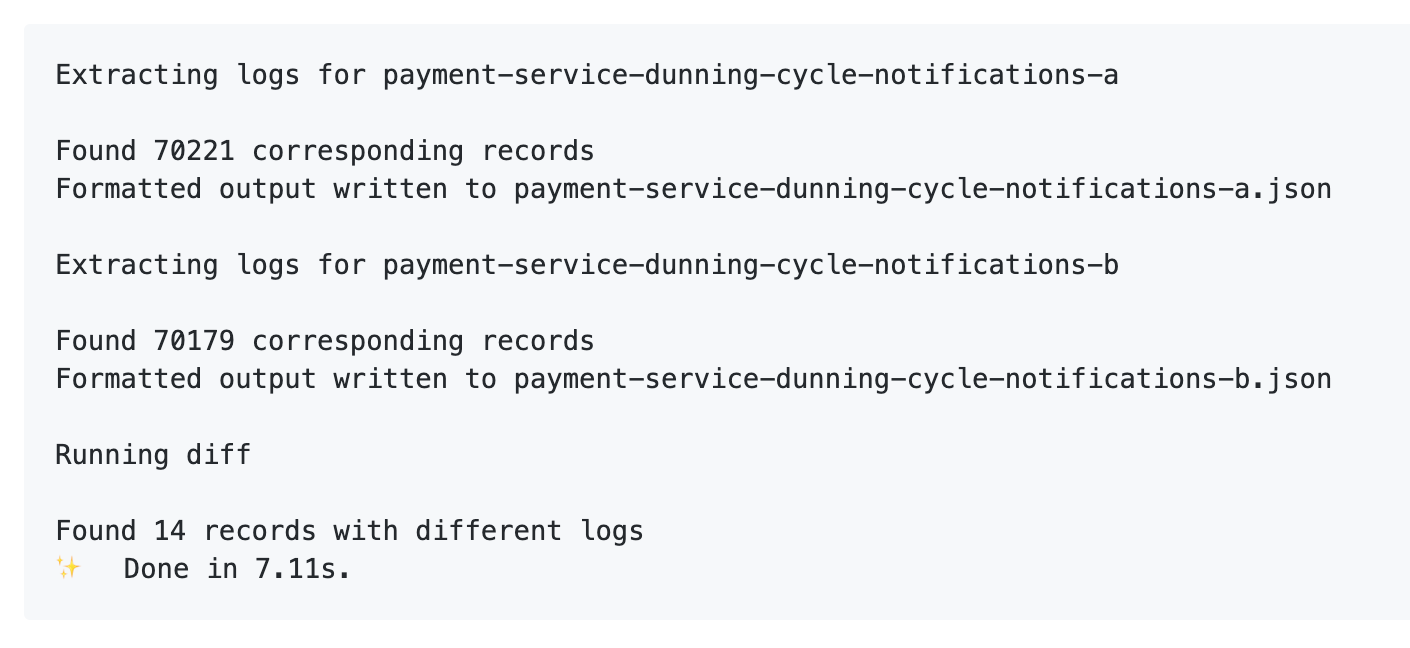
Another thing it can do is automatically handle expected differences. If you expect a difference in behaviour between shadow and master runs, you can describe this difference to the diff tool, and it will skip it from the final diff.
The tools currently are quite specific to our needs, but we might as well open source them at some point, if they become truly useful beyond the boundaries of our team.
Next steps
In my mind, the ideal scenario would be having a shadow test run as part of the CI build. This could be one of those optional steps in the new Circle CI flows where you can let it run a shadow test when needed.
Running shadow tests is time-consuming. In our case, a single run can take up to an hour, after which you need a human to fetch the resulting logs, generate a diff and look for regressions. This can be automated further - you initiate the test, it runs in the background, generates a diff and posts it to you personally on Slack if there are regressions detected. Pats you on a shoulder if not.
Further reading
Tesla shadow testing https://www.forbes.com/sites/bradtempleton/2019/04/29/teslas-shadow-testing-offers-a-useful-advantage-on-the-biggest-problem-in-robocars/
Also watch Tesla's presentation from their AI day - specifically on how they use shadow mode to deploy increments to their autonomous driving model: https://youtu.be/Ucp0TTmvqOE?t=7892
Traffic shadowing with Open Diffy https://github.com/opendiffy/diffy
Traffic mirroring, also known as traffic shadowing, provides a powerful way to bring changes to production at the lowest possible risk. The mirror sends a copy of real-time traffic to the mirroring service. Mirrored traffic goes outside of the critical request path of the main services.
Alibaba and traffic comparison https://www.alibabacloud.com/blog/traffic-management-with-istio-3-traffic-comparison-analysis-based-on-istio_594545
Testing in production - the safe way https://medium.com/@copyconstruct/testing-in-production-the-safe-way-18ca102d0ef1
Feedback
Are you using shadow testing in your company? Let me know and let's catch up and talk! You can drop me a line to hello@alexsavin.me or send me a message on Twitter: @alexsavinme