Snapshot based persistence
Let’s talk data.
An average web app would likely have some sort of a frontend, a backend and a database. The frontend would display the form, the backend would receive the form contents, and a database would be a place to persist the form forever (or at least until a catastrophic failure of a particular region of your instance).
Consider a scenario when a user buys a train ticket. We’d have a data model for a user, and a data model for a ticket.
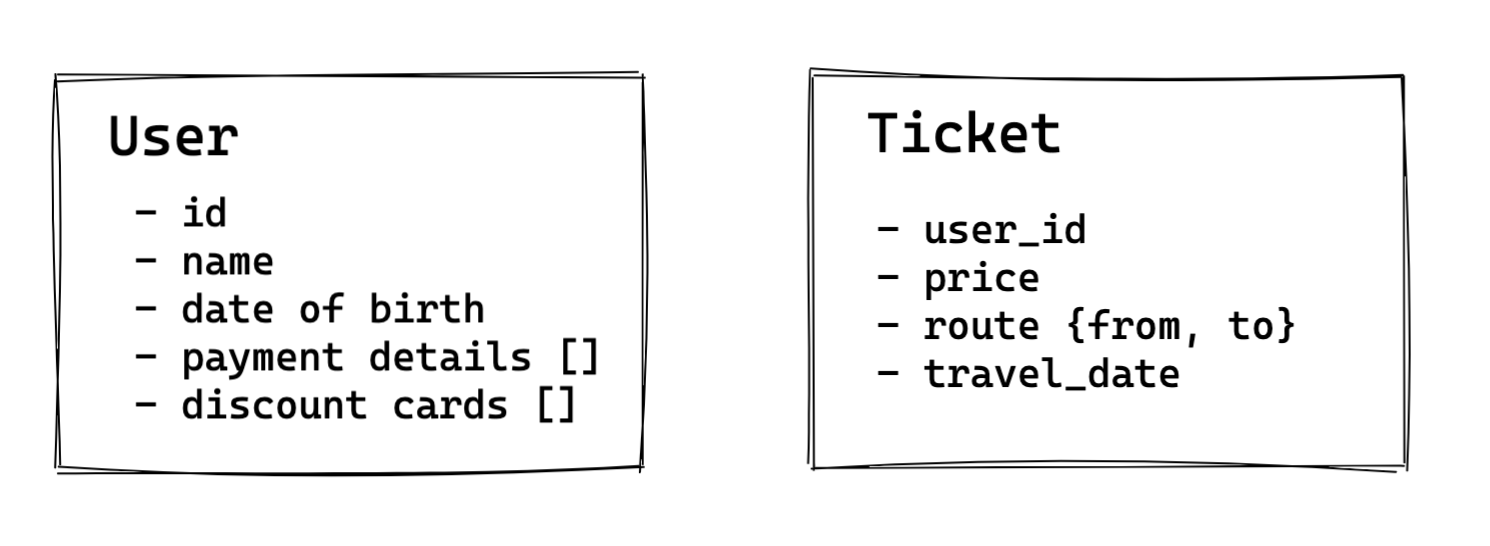
USER
- id
- name
- date of birth
- payment details []
- discount cards []
TICKET
- user_id // aka who bought the ticket
- price
- route {from, to}
- travel_date
A ticket is linked to a user via something called “foreign key” - a unique identifier of a user record. This way we can easily find out all the tickets that belong to a given user.
This is great, but let’s say our business insight would like to know how many users aged under 30 bought tickets for August this year? Not a problem - you might say - everything we need to get this data is already there. Just a few easy steps.
- Fetch a list of users for August
- Calculate their age based on the current year and their date of birth
- Filter by the resulting age, only returning users with the requested age range
But what if we could simplify this dramatically? Enter data snapshots.
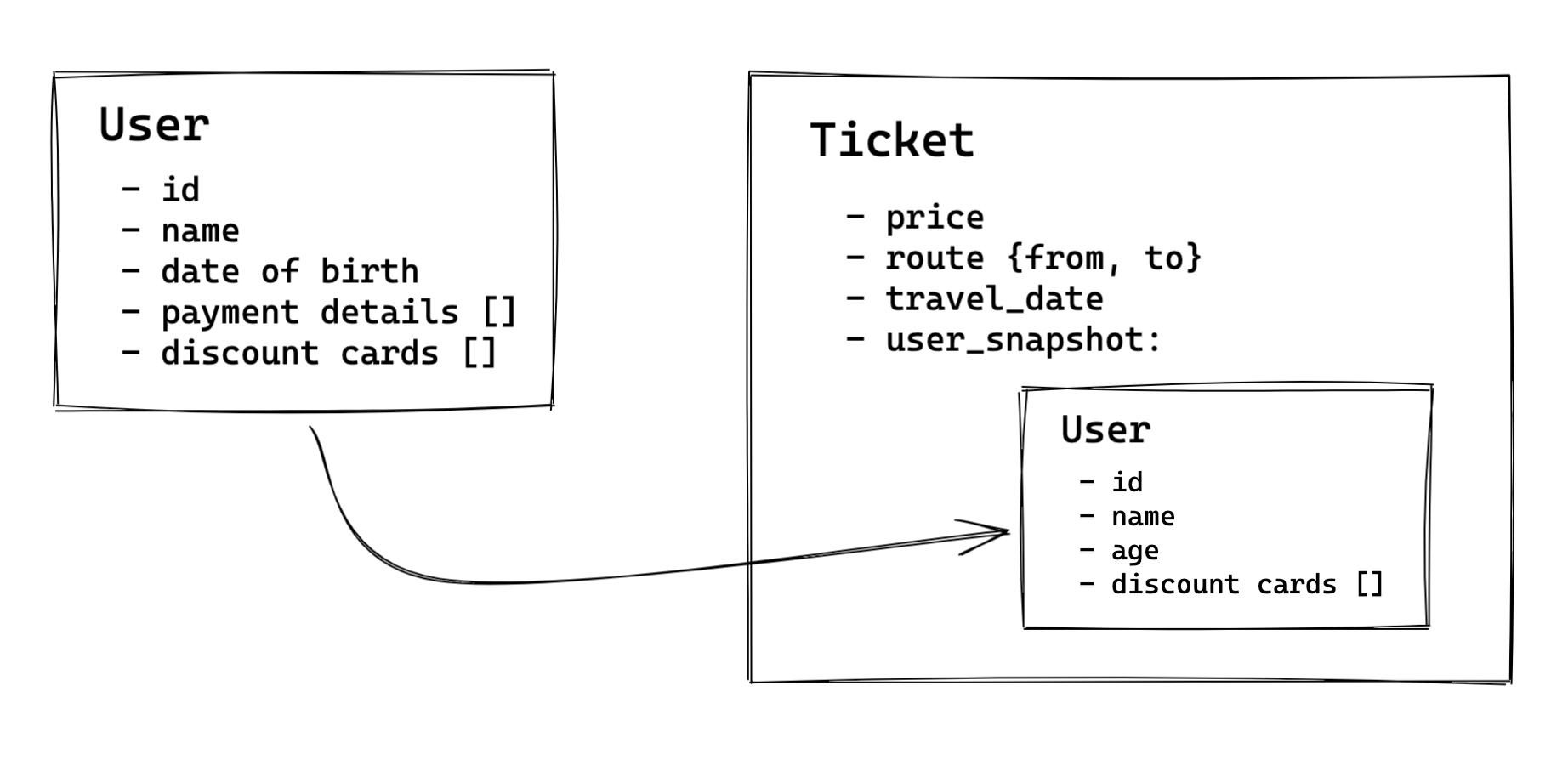
TICKET
- user_snapshot
- id
- name
- age
- discount cards []
- price
- route {from, to}
- travel_date
What’s changed? We have “snapshotted” the user’s age onto the ticket record. Age value is constant when it is related to a given date. If you are 30 at the moment of buying a ticket, that fact will never change for this particular life event. So we might as well snapshot this at the moment of saving the new ticket.
Note that we’ve also snapshotted the user’s name and discount cards valid at the moment of purchase. This is also something that can change over time. However for this particular ticket, it will remain constant, and we want to keep track of that. Think of this - if we simply link to a user document with a foreign key, and a user changes their name, we might never be able to recover what legal name was used originally for a purchase of this specific ticket. The same goes for discount cards - they expire and gets updated all the time.
Snapshotting vs single source of truth
In a PLOP (place oriented programming) world data snapshotting idea might be something almost inappropriate. This is effectively data duplication. You consume precious disk storage by being “lazy” during runtime. Calculating user age is straightforward enough, and why would you pollute the database with easily calculable data?
Good thing we live in a world when disk space is cheap.
Don’t get me wrong, there are still plenty of scenarios when you should be concerned about duplicating data left and right. A single source of truth principle still makes total sense. Furthermore, a snapshot is immutable by definition, and when a parent data changes, a snapshot will remain the same. Hence it is important to understand when using snapshots is a good idea, and when you should still use a good old link.
A good scenario for snapshotting might look like this:
- A stored entity has a property of “created_at” (this might be a moot point since chances are you will get this by default from most DB engines today)
- A data we are considering for a snapshot can change in the future and there is no other way of tracking this change
- We want to persist the state of the system in regards to a particular event
- When parent data is updated in the future but its snapshot remains the same, we are 100% ok with that
Snapshotting can also be useful for the pre-computation of data that could take a lot of time to compute across millions of your users.
A more complex scenario
Thinking in snapshots can be helpful in surprising places when other workarounds could be more cumbersome and difficult to maintain.
Consider the following example.
UserDetailsFormFields
- first_name
- last_name
- DOB
UserProfile
- id
- user_details_form_fields_snapshot
- first_name
- value
- last_name
- value
- DOB
- value
In this case, the user registration form is defined dynamically and can be altered by the system admin. We have a bit of a data-driven UI here. We might want to add more fields in the future or amend existing ones. However, if we do so, we would have to migrate all existing user profile records to align with the updated form schema - or risk page load failures on the client.
(to be completely honest here - we might still want to migrate existing user profiles - in addition to snapshotting)
Since we are talking about dynamic form schemas, it would be safe to assume that the client-side is capable of rendering such form based on the provided schema details. This is where snapshotting comes in handy. Because we have snapshotted the original form schema at the moment of user profile creation - now we can safely render the form on the client, even if the original schema is changed.
Origins
In a document-based database, joins can be pretty expensive. That is when you need to combine data from multiple documents to respond to a particular request. This is less of a problem in the relational DB world, but even then sometimes you might end up with some insanely complex JOIN statements spanning many, many tables.
This is when Data Denormalization is usually mentioned. In an essence, this is when we pick a part of a document and copy it into another document. Good old copy-paste, which might or might not have a reference to the source. This solves a JOIN complexity by putting all the data into a single document - at the expense of the increased size of the document.
What can possibly go wrong
So many things. Using data snapshotting requires a certain discipline, which - in larger teams - should be agreed upon with everyone working on the product. A general convention of snapshot immutability should be well understood and maintained.
Otherwise, interesting things start happening.
The most common failure would involve a snapshot of mutable data. It’s possible to end up in a situation when the source document of the snapshot is changed without updating the snapshot(s) across the database. This way the source document is updated, but the snapshot remains old.
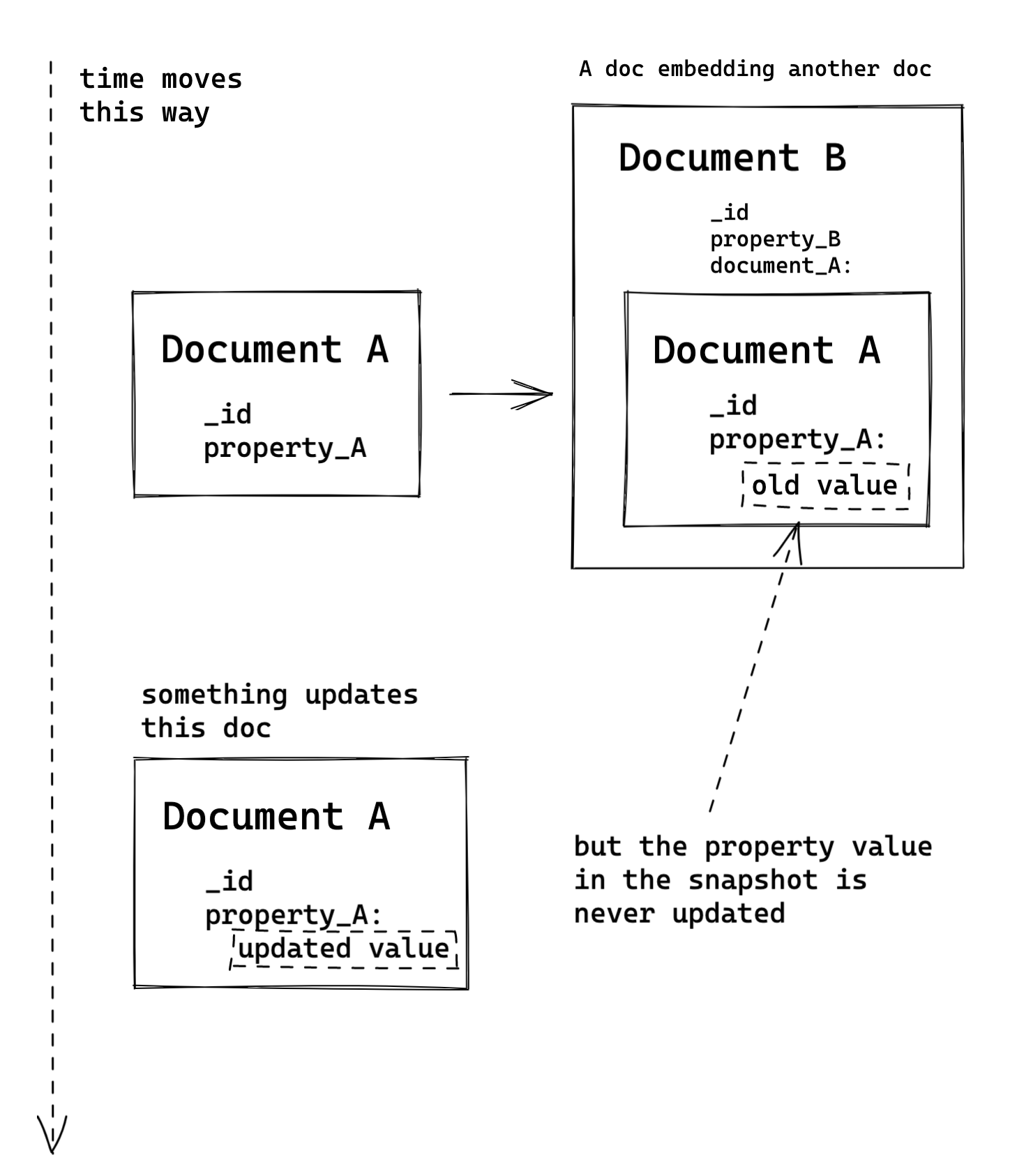
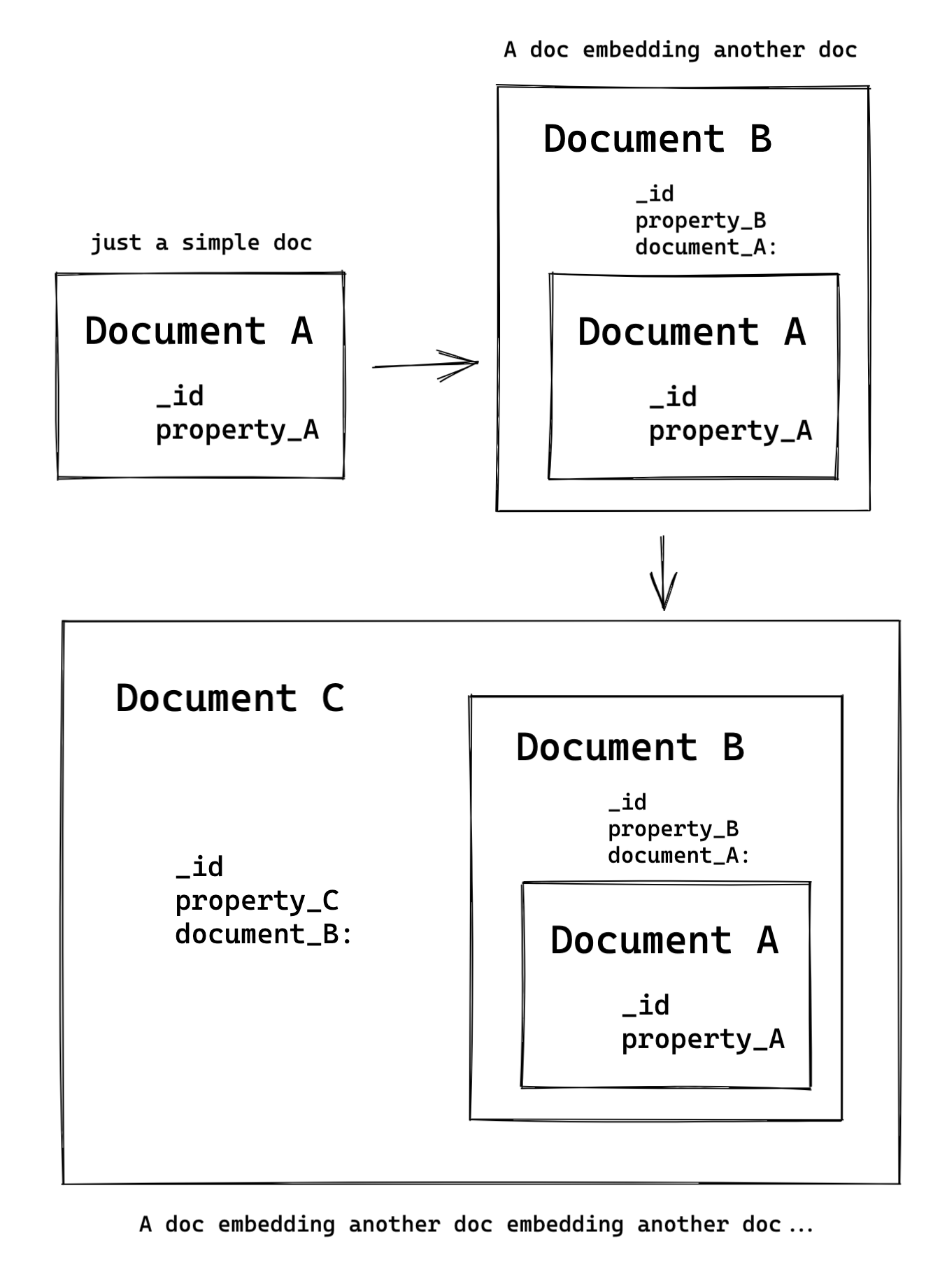
Complex snapshotting would be another issue. When snapshotting an existing document as a whole, we embed a verbatim copy into another document. If then another bit of business logic decides to snapshot that document, it will have existing snapshots embedded too. This could end up like one of those fractal pictures when nesting can go on for a while, introducing all sorts of issues.
Some final words
Data snapshotting is one of those tools on your belt that might not solve all the problems, and be applicable in every situation. However, under a specific set of circumstances and when used right it could be the exact tool you need. This is a convention that is not particularly set in stone, and so can be heavily adapted for a given use case, and combined with the existing functionality of a backend or a database engine.