GPT-V vs Selenium
Most of software testing always been fairly deterministic. You’d expect a certain button to be in a certain spot, and behave in a very specific way. Given a very specific input, you assert on a very specific output.
Determinism means fragility, and while it takes a lot of time to write such tests, they would also break easily, sometimes even when they shouldn’t.
Have you ever written client tests with Selenium and Cucumber? Things are about to change.
Today I’m able to upload webpage screenshots to GPT-4 with Vision support and ask questions about it. Current version of the model is also able to browse static webpages, but for now it refuses to run JavaScript. No doubt this limitation is temporary, and even today there are a few ways how we can get around it. Even with screenshots you can enable a lot of non-deterministic UI testing, that might fundamentally change the way you structure tests.
Users, after all, don’t really care about specifics. They want a way to login and use your web app. And the business wants users to be happy.
The kind of prompts you can run against a screenshot of a webpage today include:
- Specific instructions for a UI element that is expected to be present - “Make sure there’s a green button with text About on it”
- Vague instructions for expected user interactions - “Could you make sure the users can find a way to log in?”
- Accessibility evaluations - “If you are a color blind user, would you be able to find a way to log in?”
- Exploratory navigation - “Could you list all the links at the tabs on top of the page”
If you are developing one of the more popular websites, chances are the model will recognise it, and already will know exactly how to use it and what it is for. This is happened when I was feeding it Github screenshots - it effectively assumed a role of a Github user, very well aware of what Github is, without me ever mentioning the context.
Not just Selenium
Non-deterministic testing is a challenge also in e2e and contract tests. For a complex system, controlling state is always a challenge. Even on staging environment you are often unable to simply reset all the databases for the sake of your acceptance run. And yes, with proper data hygiene anything is achievable, but the efforts involved are often not worth it.
I prefer the “pit of success” approach. Anything you try leads you further and further towards your goal. Which is, hopefully, stable, easily maintainable software, with happy users.
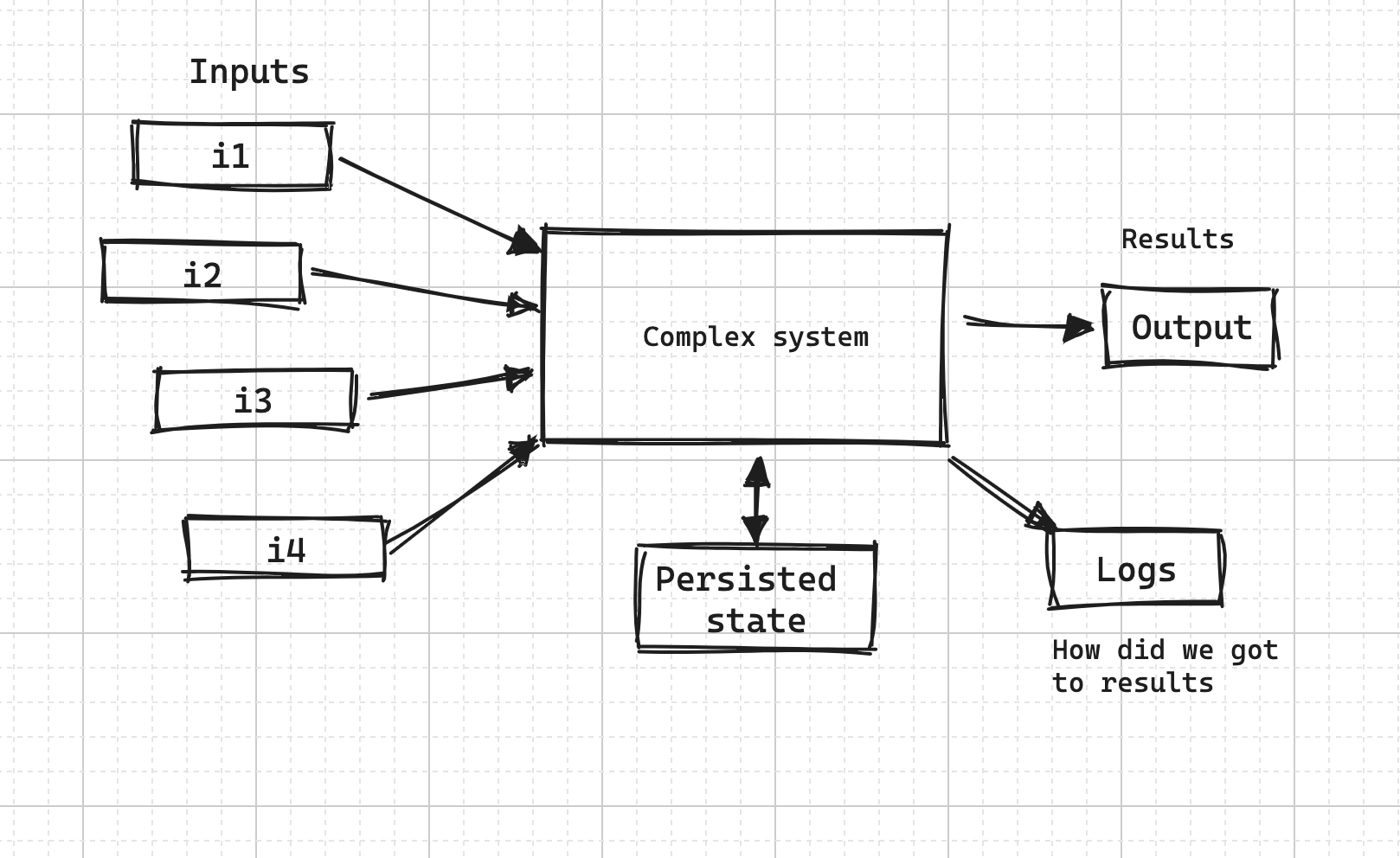
Traditionally your app would receive a number of inputs - some as part of an incoming request, and some - sourced from internal and external storage. Once all inputs are sourced, a set of business logic would run, and eventually produce an output. The output would only contain the “ultimate answer”, and no explanation on how we got there. The logs might contain some hints on how we got to the answer.
When an app crashes, it would usually produce a stack trace, leading to the point of crash. I’d say we could produce something similar for evey successful request too - explaining the internal thinking and logging all the details. This is always something that is useful for developers when trying to figure out a particularly complex business logic - but is also something you could feed to an LLM and ask if given all the inputs and state of the system, the outputs make sense?
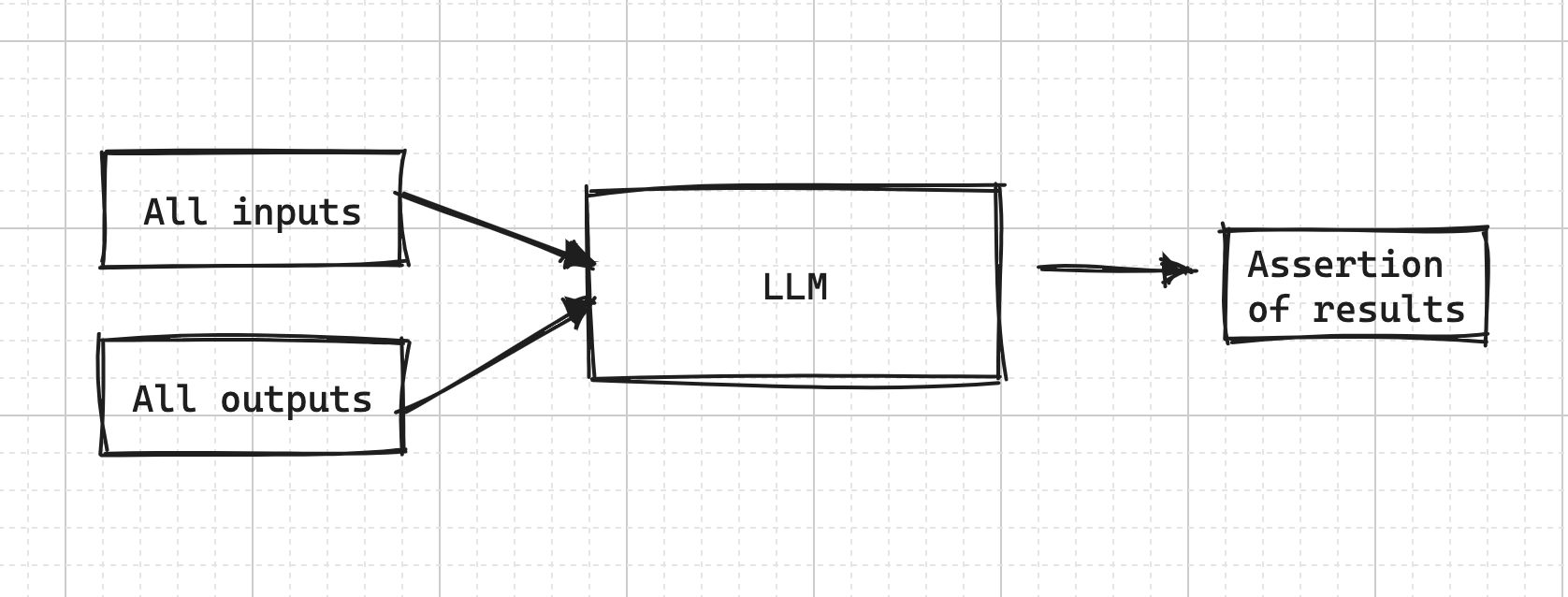
Of course, the stack trace should always be disabled on any kind of live environment, and good practices should be applied in case of a risk of a PII spilling. Not every data is good for logging.
Non-deterministic testing for backend could make things very interesting, and more reliable in the long run - given there are enough signals for the test to run the assertion.
Where are we today?
Here’s an interesting project that uses Vimium browser extension to enable page navigation: https://github.com/ishan0102/vimGPT
I’d expect a full support for web browsing soon, as well as an autonomous AI API for a web browsing agent. For backend we might have to build things ourselves, since every complex system is somewhat unique. Like with shadow testing, you’d have to custom tailor it to produce explanables of the output - a trace of internal business logic that would allow assertion of the result.